这就是VV——项目开发幕后
2025.05.28
技术 开源
近两年越来越多的人开始使用张维为的表情包,流传在网络上的梗图也越来越多,我的手机相册里也存了一大堆。但是当存储的表情包过多时,在聊天时找到那个最合适的表情包就很难了,查找的效率也会大大降低。那有没有什么方法既能存储巨量的表情包,又能够快速的查找到最匹配当前语境的方法呢?于是「这就是VV」项目便在我的脑中诞生了。
从0到1
构思
其实这个项目大体上的结构在一开始就定好了,一开始就想着把《这就是中国》节目的所有台词和VV出现的视频帧提取整合,最后再加个搜索。为什么不用收集网络上流传的表情包呢,主要还是质量和数量两方面的因素。网络上的表情包质量良莠不齐,有的分辨率高有的分辨率低,也不知道是谁第一个找到的,再者《这就是中国》更新了200多集,每集45分钟上下,那么多张图也不可能有人靠着手动的方法把它收集全,因此只能靠OCR和人脸识别把所有剧集都跑一遍了。
相关技术
解决这个问题最大的困难应该就是人脸识别相关的技术了,如何准确的识别VV的脸确实是一大难题。为此我尝试了多种方法,包括但不限于自己从零开始构建一个人脸识别的训练网络,再手动找一些VV的脸,统一裁切成相同的大小进行训练,构建出一个专用的模型;找一些开源的人脸识别框架进行人脸识别与匹配…最终并非最终选择了使用dlib进行人脸识别的方案。
关于字幕识别方面,我只能说B站太坏了,这个剧集竟然没有字幕一开始大概就想好了用哪个方案,那便是ddddocr。用这个库进行OCR,主要是之前在帮朋友写一个抢课小脚本时,发现这个库针对验证码的OCR能力较强,想必它对普通视频字幕的识别也比较友好了。
再接下来就是将这两者结合起来,先以每秒一张的频率截出视频帧,再对每一张图片进行人脸识别,取和VV人脸相似度最高的人脸做记录。再对这张图片中的字幕进行提取和识别,最后将字幕的文字、对应这个字幕的人脸相似度和时间戳保存至一个同JSON文件中以便查找。最后存放的数据格式如下:
|
|
CPU?GPU!
跑了没多久我就发现,怎么会这么慢捏?一看任务管理器原来是CPU有难GPU围观。面对260多集近150G的视频数据,我有点绷不住,照这个速度跑下去,不是一两天能够跑完的,就算我有一颗12900HX和一颗残血M1Pro,跑完所有的数据所消耗的时间仍然是较大的,在此期间我还不能拿电脑干其他重活,这是我不能忍受的,于是我便开始研究如何使用GPU加速进行运算。好在dlib的GPU加速配置并不是很困难其实我现在都忘了怎么配的了,在配置之后速度便大大提升,我的4070Laptop也算是有了用武之地了。
抛砖引玉
在提取出所有的视频数据之后,需要解决的就是搜索的问题了。面对数十万条数据,以现代处理器的性能进行搜索也是小菜一碟我这种喜欢写屎山代码的人有救了。要解决的问题主要就是模糊匹配,用AI随手糊了个代码完事(难绷),然后一个基本可用的网站就实现了。
项目完成后,便是找个地方宣传宣传看看效果听听反馈了。于是便首先在知乎问题为什么张维为的大量表情包会在网络上走红?下抛出一个回答,宣传了一下这个项目。过了几天浏览量竟然有小几万,也有一百多条评论,也提出了一些建议,不过有些较难实现的功能由于水平不够所以就没去多想。直到一天早上起来后发现GitHub的项目仓库中多了一个PR……
这个PR主要改进了人脸识别和字幕OCR的准确度。在人脸识别方面,使用的是insightface的方案,字幕OCR部分则使用的是PaddleOCR。在进行一小部分的测试对比后,我发现这个方案比之前所使用的方案好出了一大截,人脸识别准确度的问题得到极大提升,并且在侧脸识别方面有了极大的加强。至于字幕识别,准确率也得到了很大的提升,不会识别出一些奇奇怪怪的字符出来。
然后就是对正常用户感知最强的前端页面了,在此之前,前端是长这样的:

这个瞎糊的页面一时半会我也不知道怎么改动。说能用吧,现在看来真是一坨,说不能用吧,信息展示的挺清楚全面,也能用下去。这就导致了我没啥动力改下去我做东西一般都是将就能用就行的,直到undef-i提了PR,我才知道原来这样做又简洁好看又易用,并且还展示了对应画面的缩略图,非常直观,于是便有了现在焕然一新的页面。
再来一遍
有了新的方案,要不要再花费一些时间重新跑200集数据便成了困扰我的一大难题。新的方案使用GPU加速的环境我在Windows机子上始终配置不好,WSL前段时间被我玩坏了启动不了并且我又懒的重装,无论怎样配置都是CPU在进行计算,效率极低。又是undef-i跟我说她在WSL上跑的很快,并提交了能用GPU加速计算的commit,这才重新装了一遍WSL,配好了能用GPU加速运行的环境,总耗时一小时出头,不禁感叹要是早点用WSL就好了。
接着就是无聊的等待时间,不过由于代码的轻微改动,检测的信息变多,发现了一些神奇的地方,例如第73集的画幅比例正常应该是16:9的比例,但不知道为啥被压扁了一些;还有一些视频的文件格式(具体说应该是编码格式)和其他的视频不同之类的。
从1到100
在B站宣传
提高了各个方面的准确率,并且对数据进行一定的优化之后,我打算在B站做一个视频推广一下这个项目,看看评价如何。便画了大半天时间,用AI生成的VV语音给视频配了音,对整个项目的诞生和使用方法做了简单的介绍,然后便把视频上传了。
令我没想到的是,没过几天视频竟然火了起来,还上了B站的热门:
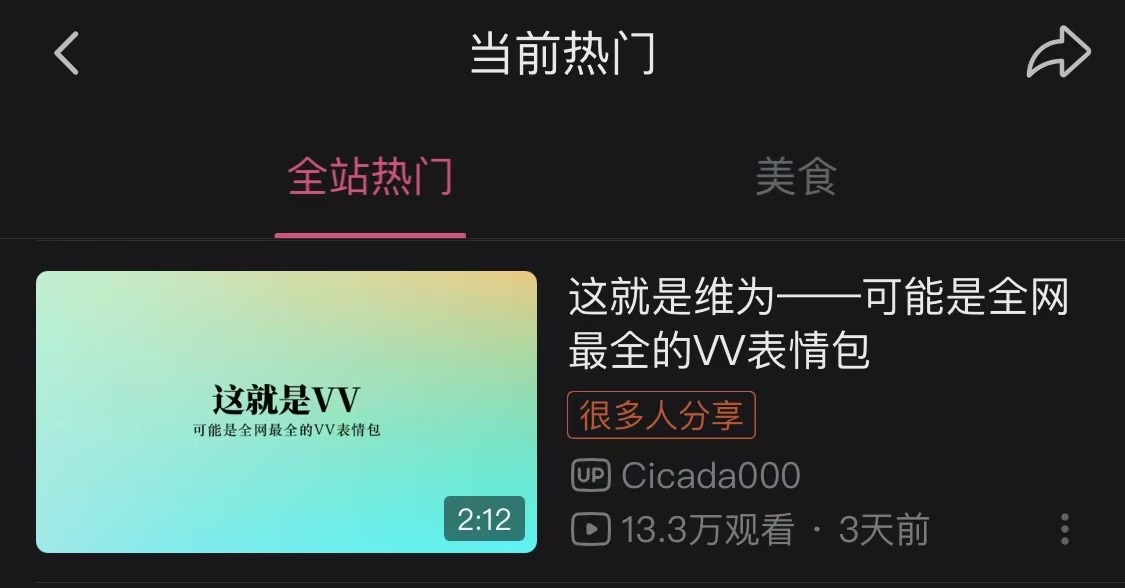
这一下属实有点震惊到我,在热门上的时候最高有1000+人同时在观看,“那应该会有很多人访问我的网页了吧…”我这么想着,此刻的我并没有意识到什么,直到…
一封邮件
我清楚的记得那是一个周二,大早上的起床上着数据库的课,觉得无聊便打开了邮箱看看有没有什么邮件,然后便发现了Vercel发来的一封邮件。前面我还以为是什么推广的邮件,然后我定睛一看:Approaching your limits:Upgrade now to avoid service disruption
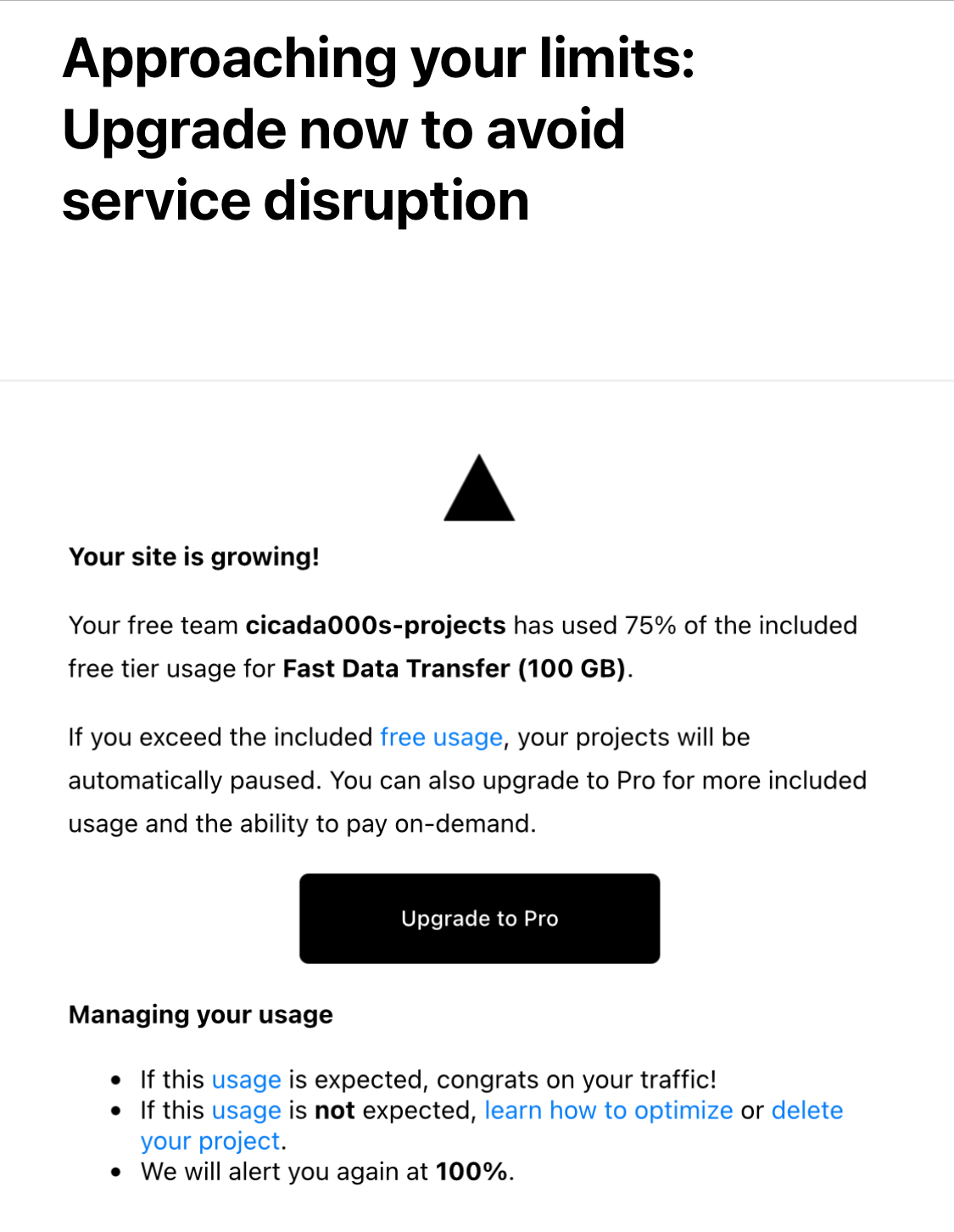
看到这个邮件后,我急忙打开Vercel查看项目的Usage,再一看,我又愣住了:
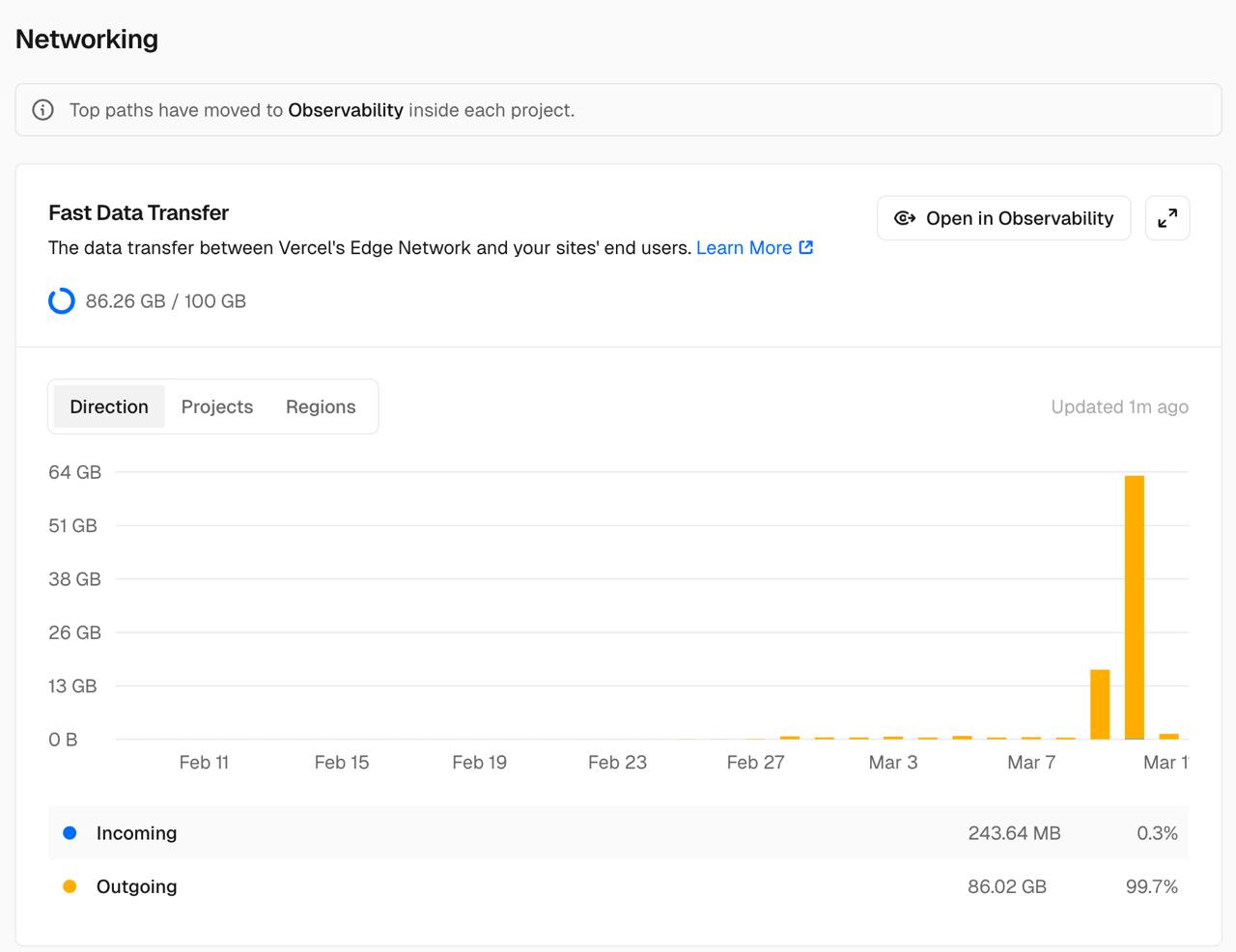
在上了热门后的一天内,这个项目直接跑掉了我60多G的数据,要知道Vercel给个人开发者的每月额度是100G,照这个数据下去,再过几个小时就会因为用满额度停止服务了,我可不想在这个高峰期白白损失这么多用户。于是我当场决定——再注册一个Vercel账号顶一顶先(现在看来这个操作确实抽象,但当时电脑不在身边,其他操作太麻烦了)。
另一个账号顶了四个小时后,我又看了下数据,又是大吃一惊:
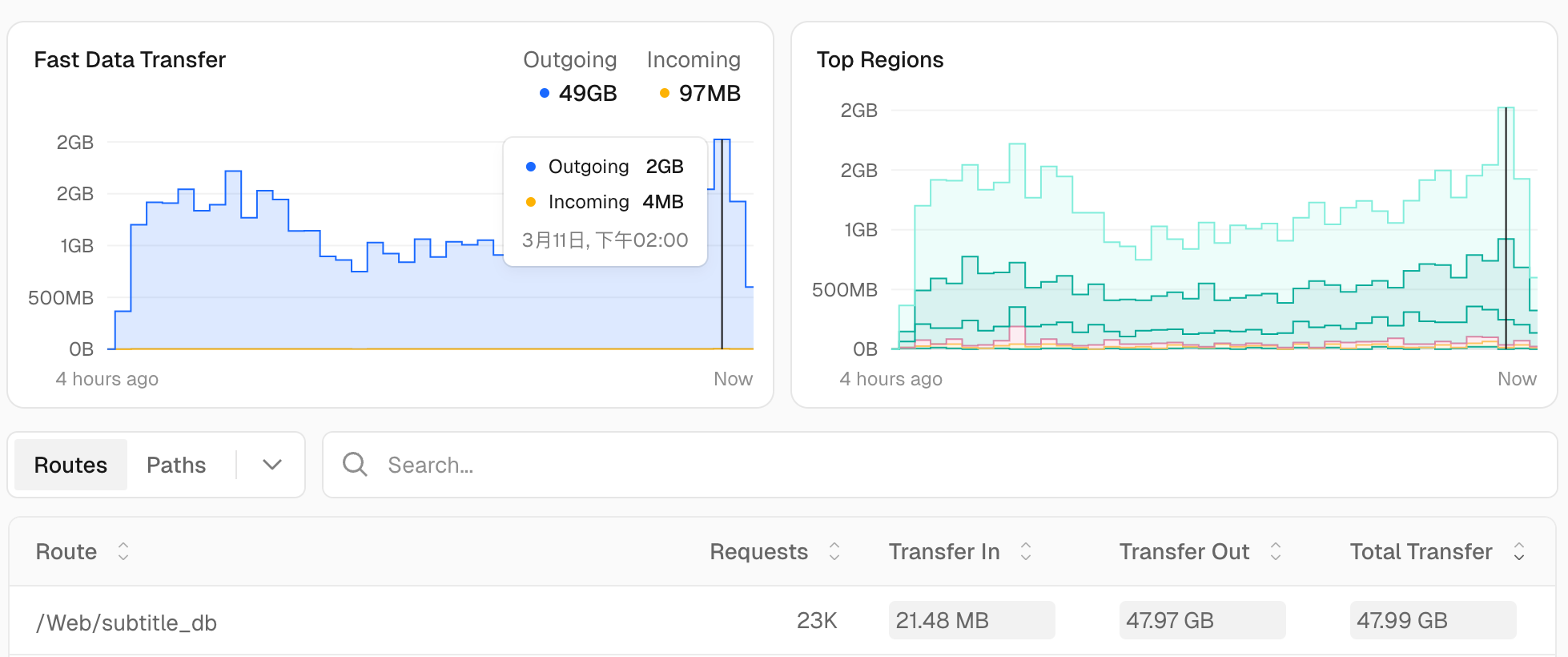
仅仅四个小时就用了50G的数据,看来只有两条路了,要么交钱充会员,要么换服务商。而我又是一个穷学生,充钱是万万不可能的,于是我便将目光瞄向了Cloudflare。
赛博菩萨——Cloudflare
将网页的资源和字幕数据库迁移至CF上之后,我只能说:这辈子没打过这么富裕的仗。相较于Vercel每个月100G的数据限制,CF只限次不限量,A类操作每月100万次,B类操作每月1000万次,只要不是恶意攻击应该是很难使用到这个量了。再迁移到CF上后就再也不用担心服务崩溃的问题了。后来再回看那几天的访问量和数据量统计,我只能说还好及时进行了迁移,不然后面有的好受了。
更高效的搜索
其实搜索的问题在这个项目中是一个核心问题,如何根据关键词搜索出最贴切的句子是一个很关键的点。之前在知乎和B站的评论区都看有人提到过RAG,但是我对这方面不够了解,并且我比较喜欢Serverless的部署方式,非必要时不喜欢放个服务器在后端进行运算,于是RAG的方案就搁置了。
又是wen999di在Github上提交的PR,才让我发现了一些新的可能。原来Cloudflare上有免费的Vectorize服务,可以查询嵌入。再根据PR的代码修修补补,一个勉强可用的服务便基本实现了。
实现了文本的向量查询后,结合AI进行联网搜索能进一步提高返回结果的质量。undef-i在此基础上使用硅基流动上免费的API,编写了一个部署在服务器上的脚本用于搜索。前面说到我不太喜欢什么东西都放在服务器上运行(可能是我不太会维护导致其经常会有些奇奇怪怪的问题),于是便又是改改改写屎山将其移植到Serverless平台上了事。
这么说起来我感觉自己啥也不会,全靠大佬带飞了。
尾声
修修补补,从最初的几个文件到现在这个屎山,这应该是我目前参与过最复杂的项目了。现在我彻底意识到了在项目初始阶段就规划好整个项目大体架构的重要性,以及深刻体会到了自己能力的不足。看来还是得好好闭关修炼,学更多的东西啊。
一些统计数据
3月11后七天数据:
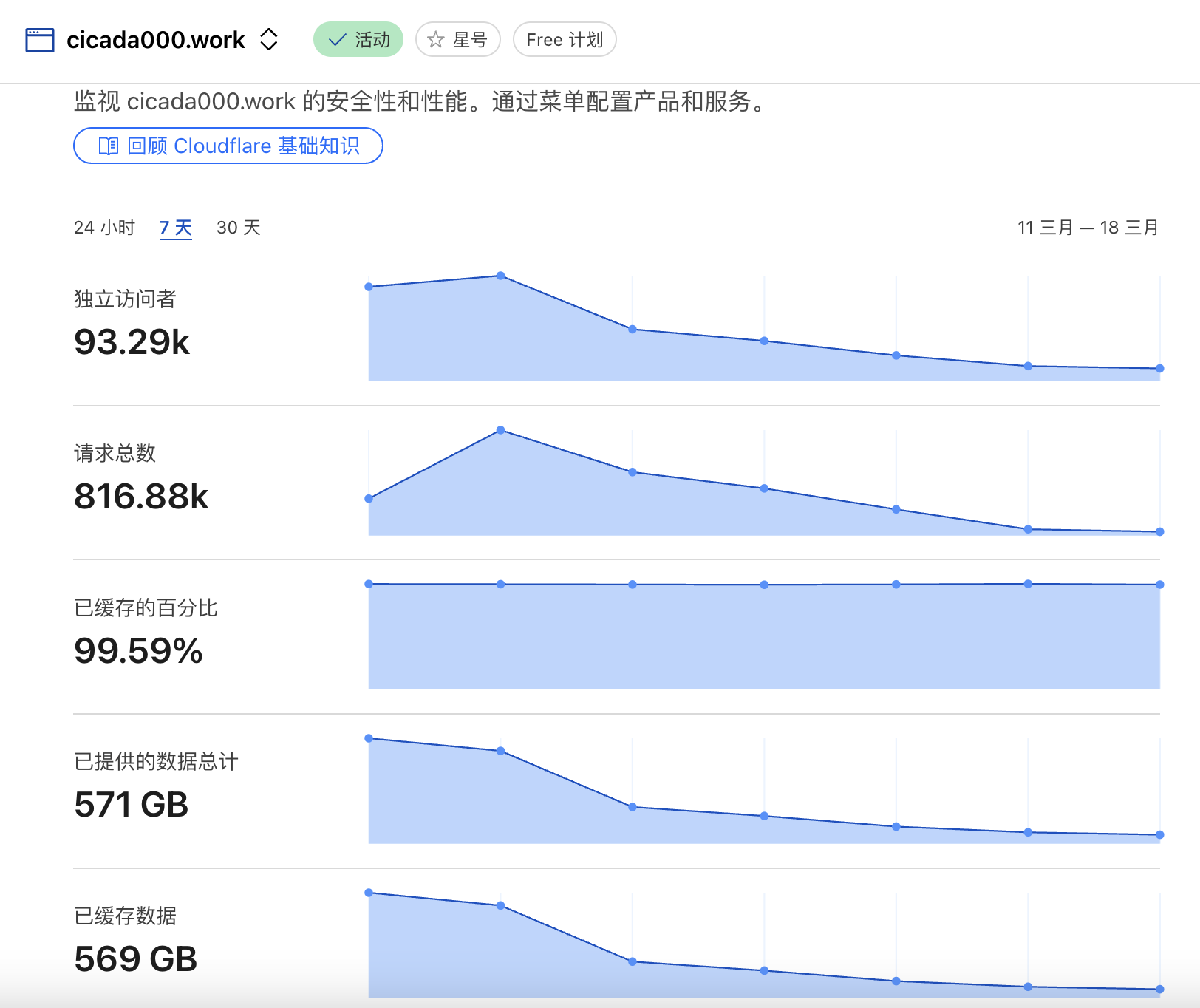
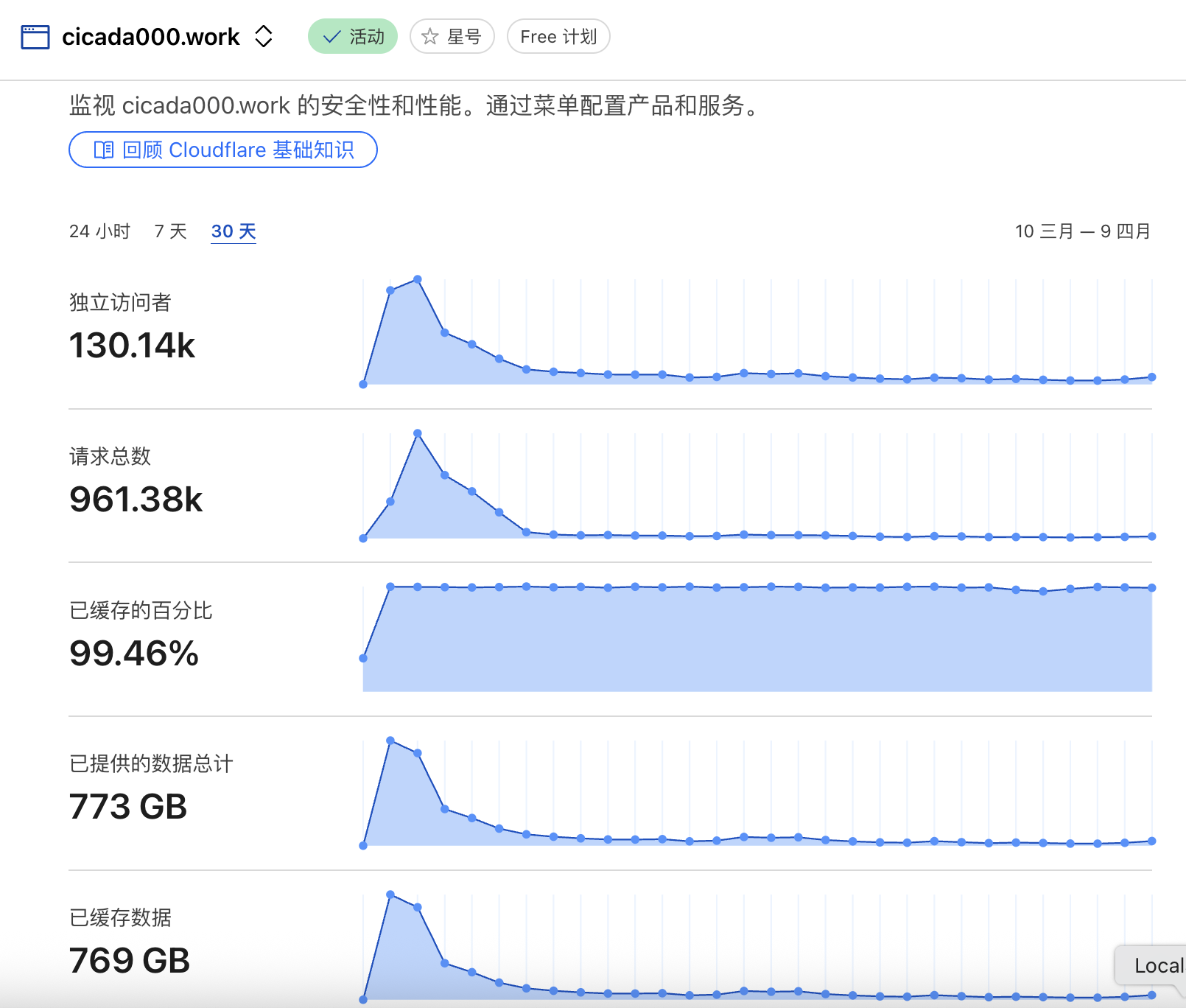
3月10日-4月19日数据:
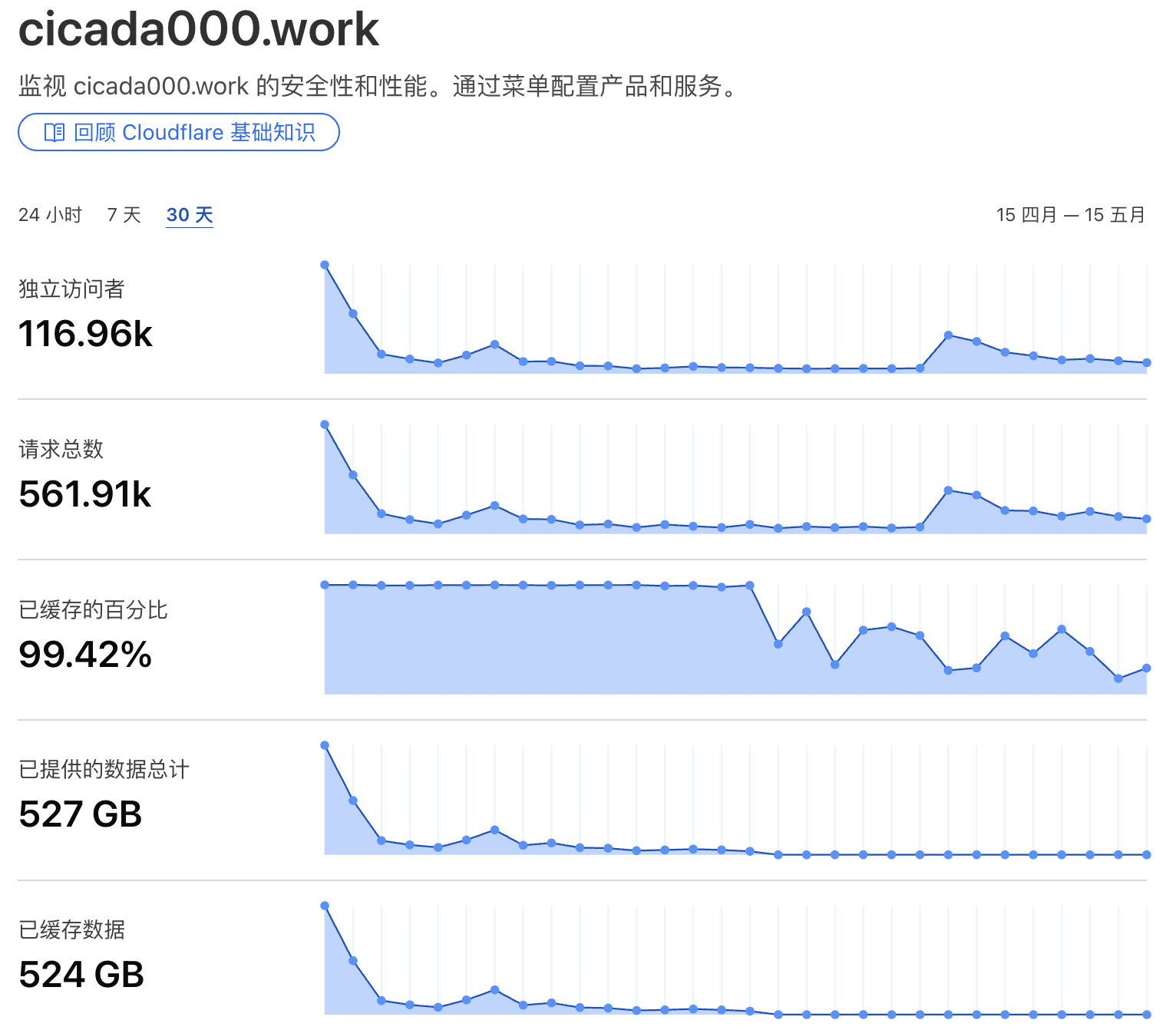
4月15日-5月15日数据:
致谢
感谢wen999di及其提交的PR,大幅提高了人脸检测准确率和字幕识别准确率,同时增加了向量检索的功能。感谢undef-i及其提交的PR,大幅提高了字幕检索速度,构建了更好看的前端页面,并且添加了GPU支持,大幅减少了新版本的人脸识别和字幕识别所需的时间。